

https://sejin-technology.tistory.com/120
이전글에 왜쓰게 됬는지 적어놨다.
HNSW이 푸는 문제가 결국 근사치에 비슷한 값을 빠른속도로 찾아가는 건데
그 문제를 ANN이라고 하는 방식의 일종이고, HNSW는 그중에 하나의 방법이다.
ANN (Approximate Nearest Neighbor)
Approximate : 근사값을 찾다
Nearest Neighbor : 근접한 이웃
- 정리하면 근사값의(대략적인) 근접한 이웃(노드)를 탐색하는걸 의미하는데
1번 문서에도 이야기 하였듯이 전체 다 찾으면 O(N) 으로 걸리니까 너무 오래걸린다.
(그냥 이대로 만들면 데이터를 수십만개 이상되면 사용자가 다 이탈해 버릴 거다)
그리고 이런 임베딩 백터들의 경우 매우 높은 고차원을 가지고 있어서 길을 찾는데 유리하지만
결국 이 많아진 고차원을 계산하는것 자체가 매우 복잡해져서 단순하게 비교해버리면
효율이 매우 떨어지게된다.
어디서 쓰는가
내가 하고 있는거 (문서 검색 / RAG)
- 상황: "이 질문과 가장 의미가 비슷한 문서 조각을 찾아줘."
- 역할: 질문 벡터와 가장 가까운 문서 청크 벡터를 ANN으로 0.01초 만에 찾아옵니다.
2. 추천 시스템 (넷플릭스, 유튜브, 쇼핑몰)
- 상황: "이 영화를 본 유저가 좋아할 만한 다른 영화는?"
- 역할: 유저의 취향 벡터와 가장 가까운 영화 벡터를 ANN으로 찾아서 추천 목록에 띄웁니다.
3. 이미지 검색 (구글 렌즈)
- 상황: "이 신발 사진이랑 똑같이 생긴 신발 찾아줘."
- 역할: 사진을 벡터로 바꾸고, 수억 개의 상품 이미지 중에서 가장 비슷한 모양(벡터)을 ANN으로 검색합니다.
4. 이상 탐지 (보안, 금융)
- 상황: "평소 거래 패턴이랑 너무 동떨어진(거리가 먼) 이상한 결제 찾기."
- 역할: 대다수의 정상 데이터 벡터들과 거리가 먼 데이터를 ANN 역발상으로 찾아냅니다.
최근에 만들고 있는 나라장터 공고분석 시스템의 경우에도 추천시스템이 있는데 HNSW 알고리즘을
이용한 Chroma DB를 사용해서 추천시스템을 만들었다.
비유하자면
[상황: 서울시민 1,000만 명 중에서 나랑 키가 제일 비슷한 사람 찾기]
- Exact NN (완전 탐색):
- 1,000만 명을 운동장에 다 세워놓고, 내가 줄자를 들고 한 명씩 다 재본다.
- 장점: 무조건 진짜 1등을 찾음.
- 단점: 1년 걸림.
- ANN (HNSW 등):
- 사람들을 대충 키별로 그룹(동네)을 나눠놓음.
- "너 180cm야? 그럼 A구역으로 가봐." -> A구역 감.
- "여기서 대충 훑어보니 저쪽 무리가 비슷하네." -> 그쪽으로 감.
- "이 5명 중에 제일 비슷한 사람 골라."
- 장점: 1분 만에 찾음.
- 단점: 진짜 1등이 옆 동네에 숨어있었을 수도 있음(아주 드문 확률). 하지만 찾은 사람도 나랑 키가 거의 똑같음.
요약
구분 내용
| 정의 | Approximate Nearest Neighbor (근사 최근접 이웃 탐색) |
| 핵심 | 모든 데이터를 다 뒤지지 않고, 지름길(인덱스)을 통해 정답 근처로 바로 가는 기술 |
| 목적 | 속도 혁신. (정확도를 미세하게 포기하고 검색 속도를 극대화) |
| 구현체 | HNSW, IVF, DiskANN 등 (ChromaDB는 이 중에서 HNSW를 사용) |
궁금한점이 O(N) 과 O(log N)의 속도 차이
logN 이라는게 직관적으로 이해가 잘안된다.
일반적으로 공부해본 알고리즘 문제들에서는 보통 피벗같이 중간에 짜르고 들어가는 애들이
logN의 속도인데, 걍빠르다고 생각만했지 얼마나 빠르진 생각을 안해봤다.
데이터 개수 (N) O(N) (기존 방식) O(logN) (HNSW 방식) 차이 (효율)
| 10개 | 10번 | 3~4번 | 3배 빠름 |
| 1,000개 | 1,000번 | 10번 | 100배 빠름 |
| 1,000,000개 (100만) | 1,000,000번 | 20번 | 50,000배 빠름 |
| 1,000,000,000개 (10억) | 10억 번 | 30번 | 3,300만 배 빠름 |
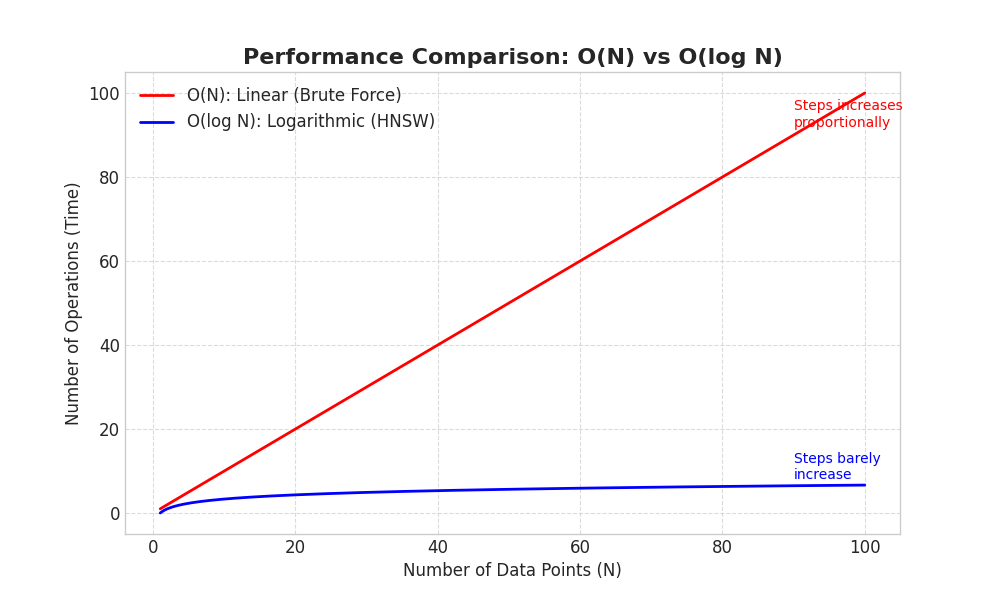
일단 컴퓨터는 이진법을 쓰니까 log_2 가되는데 이걸 절반 쪼개기를 어마나 하는지에 차이다.
그래서 한번 해봣는데 진짜 엄청나게 차이가 많이난다
// -------------------------------------------------------
// 3. 알고리즘 1: Linear Search (O(N) - 완전 탐색)
// -------------------------------------------------------
function linearSearch(arr, t) {
for (let i = 0; i < arr.length; i++) {
if (arr[i] === t) return i;
}
return -1;
}
const startLinear = performance.now();
const linearIndex = linearSearch(data, target);
const endLinear = performance.now();
const timeLinear = endLinear - startLinear;
console.log(`[Linear Search] O(N)`);
console.log(` - 찾은 위치: ${linearIndex}`);
console.log(` - 걸린 시간: ${timeLinear.toFixed(4)} ms`);
// -------------------------------------------------------
// 4. 알고리즘 2: Binary Search (O(log N) - HNSW의 원리)
// -------------------------------------------------------
function binarySearch(arr, t) {
let left = 0;
let right = arr.length - 1;
while (left <= right) {
// 중간 지점(Pivot) 계산
const mid = Math.floor((left + right) / 2);
if (arr[mid] === t) return mid;
if (arr[mid] < t) {
left = mid + 1; // 오른쪽 절반만 본다
} else {
right = mid - 1; // 왼쪽 절반만 본다
}
}
return -1;
}
js 로 만들던거 일부를 공유한다
해보면 갯수 별로해서 어마어마하게 차이가 나서 확실히 빠르더라
'알고리즘' 카테고리의 다른 글
| ChromaDB 에서 HNSW 를 이해하자 - 1 (0) | 2026.01.07 |
|---|